AI Agents — When, How, and What to Build
Learn when to build an AI Agent, the core components (LLM, tools, memory, control loop), design patterns, frameworks, and practical engineering considerations for production-ready systems.
Before diving into building an AI agent, it’s critical to determine whether your problem actually requires one. Agents add complexity, cost, and potential failure points. If a simpler approach works, use it.
Do You Need an AI Agent?
Agents shine in specific scenarios. Before committing to one, evaluate whether the problem truly demands dynamic decision-making and tool orchestration.
Decision Rules
1. If the task is deterministic (same input → same output, no side effects) → no agent needed.
Example: Formatting a JSON object to a specific layout is deterministic. A template or simple function suffices.
2. If the task sometimes requires calling external services or functions (search, DB query, API calls) → agent recommended.
Example: A customer support tool that needs to check live order status, fetch shipping info, and process refunds dynamically.
3. If you always call the same tools and always in the same sequence with a constant number of LLM calls → you may not need a full agent.
Example: A translator that always uses one LLM call + post-processing. An orchestrated pipeline is simpler and more predictable.
4. If the task requires dynamic decision-making (decide whether to call tool A or B, iterate based on results) or multi-step planning → agent needed.
Example: Automating an onboarding workflow that checks identity, creates accounts, verifies payments, and schedules meetings based on different conditions.
Decision Flow
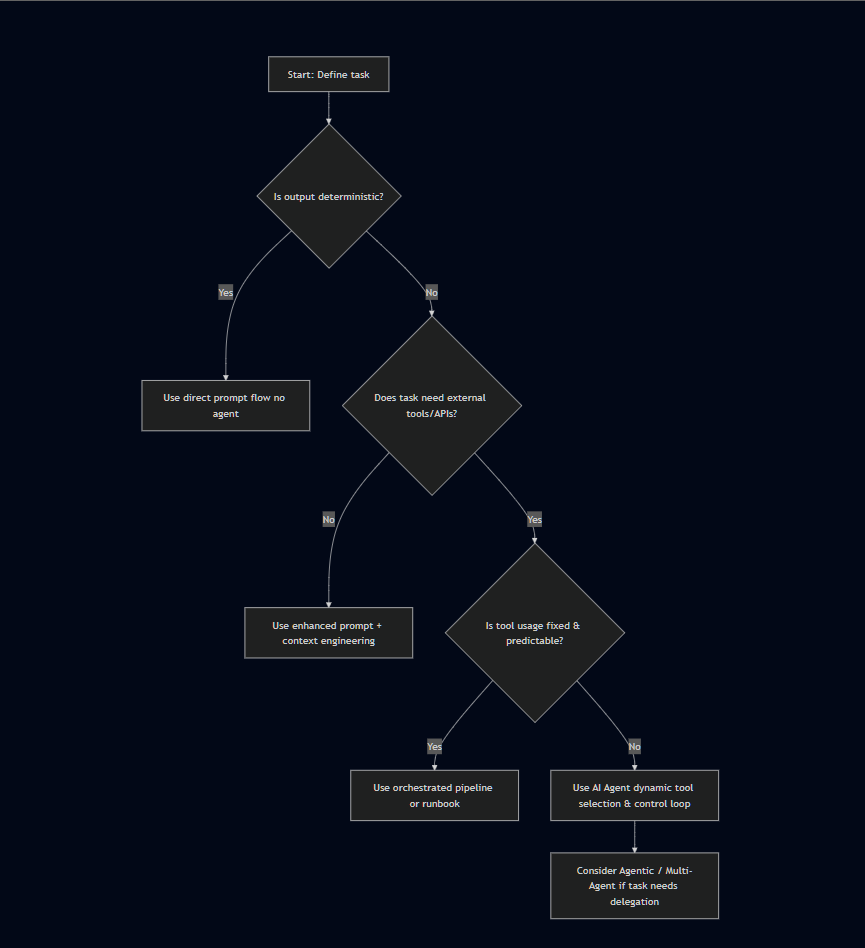 Decision tree to determine when to use AI Agents vs simpler approaches
Decision tree to determine when to use AI Agents vs simpler approaches
AI Agent — Core Components
An AI Agent is composed of multiple cooperating pieces working in concert. Here’s a clear breakdown and visual diagram.
Components Overview
- LLM (Reasoning Engine): Understands tasks, reasons, and decides next steps. Parses goals, generates plans, produces tool calls.
- Prompt Templates & Reasoning Strategy: Structured system prompt + templates that guide LLM behavior and thinking patterns.
- Tools & Actions: Functions/APIs the agent can call (search, run code, write files, etc.).
- Memory & State Management: Short-term and long-term storage for context, variables, and workflow progress.
- Control Loop: The logic deciding whether to continue, call a tool, or finish.
Components Architecture Diagram
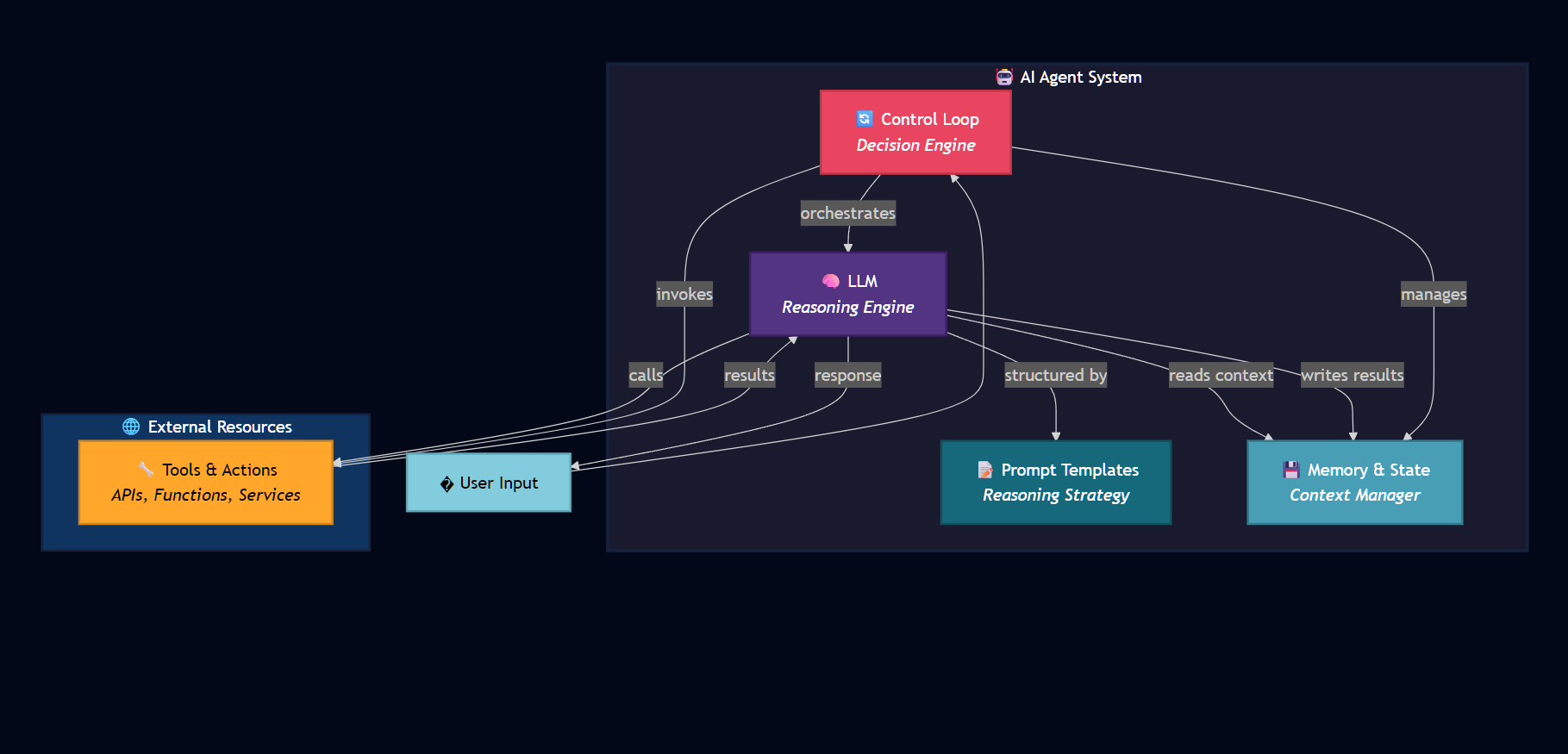 Architecture showing how LLM, Control Loop, Memory, Prompt Templates, and Tools interact in an AI Agent system
Architecture showing how LLM, Control Loop, Memory, Prompt Templates, and Tools interact in an AI Agent system
1. LLM — The Brain of the Agent
Role & Capabilities
The LLM is responsible for:
- Parsing natural-language goals into internal representations
- Producing plans (short or multi-step reasoning)
- Deciding when to call tools and how to interpret their outputs
- Communicating results back to users in natural language
Real Example
Scenario: User asks, “Create a deployment checklist and provision a staging server.”
LLM should:
- Validate constraints (quota, permissions, environment)
- Generate a step-by-step plan
- Call infrastructure APIs (tool) to provision the server
- Monitor provisioning status
- Report completion and provide next steps
2. Prompt Templates & Reasoning Strategies
Prompt templates are predesigned text structures you feed the LLM. Combine them with reasoning strategies — patterns that structure how the LLM thinks and acts.
Common Reasoning Strategies
a. ReAct (Reason + Act)
Interleaves reasoning and actions. The LLM emits: thought → action → observation → next thought.
Example snippet:
1
2
3
4
5
Thought: I should check the docs to confirm API rate limits.
Action: search_api_docs("service rate limits")
Observation: "Rate limit = 100 req/min"
Thought: Now I'll adjust the plan to batch requests in chunks of 50.
Action: call_api_batch(requests, batch_size=50)
Benefits: Clear reasoning trail, easy to debug, good for complex tasks.
b. Plan-and-Execute
Separate planning phase from execution phase. The agent first generates a full plan, then executes steps deterministically.
Example:
1
2
3
4
5
6
7
8
9
10
11
PLAN:
Step 1: Summarize repo structure
Step 2: Run tests
Step 3: Fix linter errors
Step 4: Commit changes
EXECUTE:
Run Step 1 → return summary
Run Step 2 → check for failures
Run Step 3 → run linter fix tool
Run Step 4 → commit with git tool
Benefits: Predictable execution, easier to audit, good for structured workflows.
c. Reflection (Self-Improvement)
After actions, the agent analyzes outcomes and updates its future behavior within the same session or stores learnings.
Example:
1
2
3
4
5
6
Action: search("Python async best practices")
Observation: Results don't match my query intent.
Reflection: "My search terms were too narrow (only 'async').
Next time, expand query to 'Python concurrent programming async await'
to capture coroutines, asyncio, and related patterns."
Benefits: Adaptive behavior, continuous improvement, better second attempts.
d. Tree-of-Thoughts (Advanced)
Enumerate multiple possible reasoning paths, score them, and select the best.
Use case: Complex problem-solving where exploring alternatives significantly improves results.
Example: Before choosing a database architecture, the agent explores 3 options (SQL, NoSQL, NewSQL), scores them against requirements, and picks the best fit.
3. Tools & Actions
Tools are the functions the agent can call. Implement them as safe, well-typed interfaces with clear input/output contracts.
Common Tools and Examples
| Tool | Signature | Use Case |
|---|---|---|
| Web Search | search(query) → URLs & snippets | Fact-checking, research, real-time info |
| Code Execution | run_code(language, code) → output/errors | Test patches, validate logic |
| File Operations | read_file(path), write_file(path, content) | Update docs, generate reports |
| API Calls | call_payment_api(payload) | Charge customers, fetch order status |
| Database Query | query_db(sql_or_params) → results | RAG retrieval, user profiles |
| Email/Notifications | send_email(to, subject, body) | Notify users, escalate alerts |
| Code Analysis | analyze_code(repo_url) → issues & suggestions | Linting, security scanning |
| Deployment | deploy_service(image, config) → deployment_id | Infrastructure automation |
Design Tips
- Validate and sandbox every tool. Never expose raw system commands to LLM outputs.
- Clear error handling: Return structured errors (not stack traces) so LLM can understand and retry.
- Rate limiting: Protect external services by enforcing quotas per agent execution.
- Audit logging: Log every tool invocation with inputs, outputs, and actor info.
4. Memory & State Management
Memory and state prevent context loss and enable multi-step workflows. There are two types:
Short-Term Memory
Purpose: Maintain immediate conversation or workflow context.
Example: Summarize the last 5 messages into a conversation_summary that is prepended to the next LLM prompt. This keeps the context window manageable while preserving intent.
Implementation: Store in-memory or in fast caches (Redis).
Long-Term Memory
Purpose: Persist user preferences, profiles, or documents across sessions.
Example: Store user preference {preferred_language: "Arabic"} or a knowledge base indexed for RAG (Retrieval-Augmented Generation).
Implementation: Database, vector store (Chroma, FAISS, Pinecone).
RAG (Retrieval-Augmented Generation)
Store embeddings/indices of documents. When the user asks a question:
- Retrieve relevant chunks (via semantic search)
- Include them in the LLM prompt
- LLM reasons over the retrieved context
Benefits: Cost reduction (smaller context window), accuracy (use authoritative docs), freshness (easy to update indexed docs).
5. The Control Loop — How Agents Decide Next Steps
The control loop implements the core decision-making: Observe → Decide → Act → Observe.
You must implement stopping conditions and limits to prevent runaway behavior.
Simple Loop Steps
- Read current state: Load conversation history, stored variables, progress.
- Append latest input: Add user’s new message or trigger to state.
- Check goal achieved: If stop condition met, return final response.
- Call LLM: Pass prompt + state + available tools.
- Parse LLM output: Extract decisions, tool calls, or final answers.
- Execute tools: If agent chose to call tools, run them.
- Observe results: Append tool outputs to state.
- Reflect & iterate: Optionally reflect on outcomes; repeat until done.
Control Loop Diagram
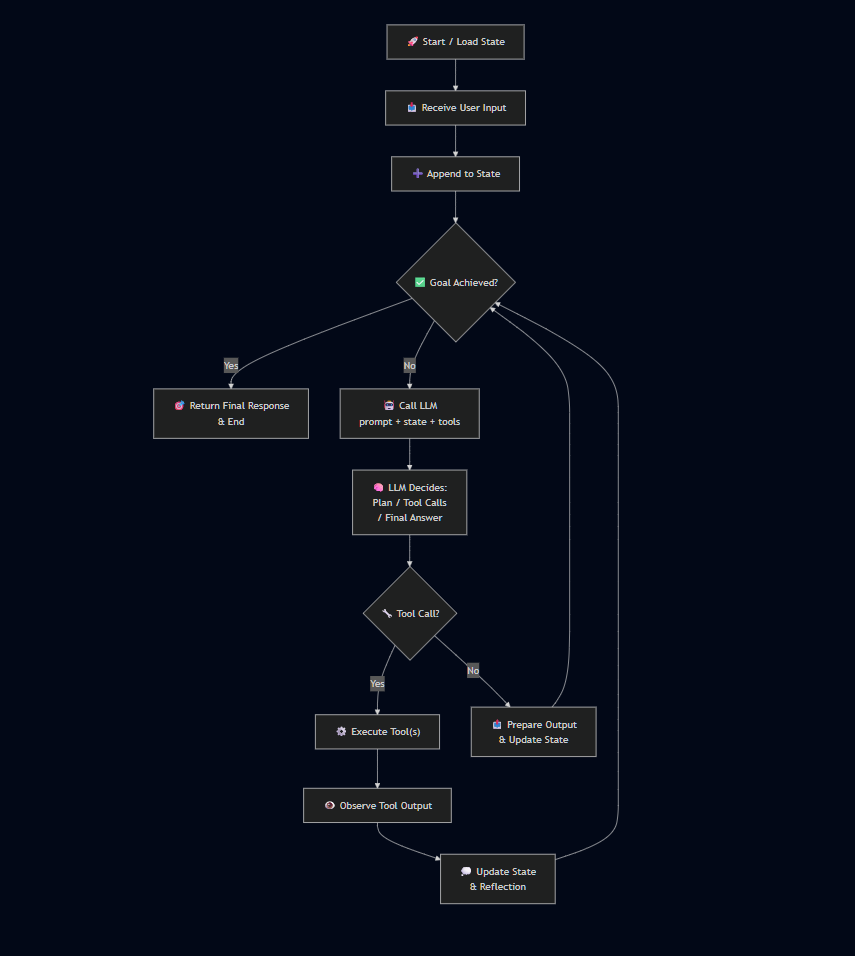 The agent control loop showing the decision cycle: Load State Receive Input Check Goal Call LLM Execute Tools Update State Repeat
The agent control loop showing the decision cycle: Load State Receive Input Check Goal Call LLM Execute Tools Update State Repeat
Control Loop: Limits & Safety
To prevent runaway or costly behavior:
- Max iterations: e.g.,
max_iterations = 20. Stop if agent hasn’t found answer. - Max tokens: Limit tokens per LLM call and total budget to control cost.
- Max time: Runtime timeout per step (e.g., 30 seconds).
- Tool call quotas: Prevent excessive API usage (e.g., max 5 search calls per session).
- Hard stop: If agent stuck for N iterations, escalate to human.
AI Agent Frameworks (Python-Focused)
LangChain
Core features: Agents, chains, memory, prompts, integrations.
Best for: Single-agent flows and RAG applications.
When to use: Quick prototyping, connecting to multiple LLM providers, building retrieval pipelines.
1
2
3
4
5
6
from langchain.agents import initialize_agent, Tool
from langchain.llms import OpenAI
tools = [Tool(...), Tool(...)]
agent = initialize_agent(tools, OpenAI(), agent="zero-shot-react-description")
agent.run("Your task here")
LangGraph
Core features: Higher-level orchestration, stateful graphs, complex pipelines.
Best for: Multi-agent workflows and sophisticated control flows.
When to use: Coordinating multiple agents, complex conditionals, visualizing state machines.
LangFlow
Core features: Visual UI to compose flows and agents.
Best for: Prototyping and non-developers.
When to use: Quick demos, no-code agent building.
LlamaIndex (formerly GPT Index)
Core features: Connecting private data with LLMs (indexing, RAG).
Best for: Privacy-critical applications, document-heavy workflows.
When to use: Building on your own docs, controlling data flow, minimizing external API calls.
Crew / AutoGen / Ray-based Multi-Agent Libraries
Core features: Orchestrating many agents with specialized roles.
Best for: Complex multi-agent systems (researcher, coder, tester, etc.).
When to use: Decomposing work across specialized agents, hierarchical reasoning.
Best Tools to Pair with Agents
Streamlit / Gradio
What: Quick interactive UI frameworks.
Use case: Build demos, operator dashboards, user override interfaces.
Why: Show agent decisions in real-time, allow manual intervention.
Datastax / Chroma / FAISS
What: Vector databases for embeddings.
Use case: RAG and long-term semantic memory.
Why: Fast retrieval of context for grounding agent reasoning.
Pandas
What: Data manipulation library.
Use case: Process CSV outputs from tools before passing to LLM.
Why: Clean and normalize tool outputs for consistent LLM input.
Redis
What: Fast in-memory data store.
Use case: Ephemeral state, session management, concurrency locks.
Why: Scale to multiple agent instances without state conflicts.
Task Queues (Celery / RQ / Prefect)
What: Async task execution.
Use case: Offload long-running tasks (infra provisioning, test suites).
Why: Keep agent loop responsive while background jobs complete.
AI Agent Design Patterns
1. ReAct Pattern
What: Interleaves reasoning and actions.
Flow:
- LLM thinks → calls search() → sees results → refines reasoning → calls summarize()
Best for: Multi-step reasoning with frequent tool interaction.
Example: A research assistant that iteratively refines queries based on search results.
2. Plan-and-Execute
What: Agent first generates a full plan, then executes steps programmatically.
Flow:
- PLAN: List all steps
- EXECUTE: Run steps one-by-one, verifying success
Best for: Structured workflows, compliance scenarios.
Example: A migration task where PLAN lists schema changes, data validation, rollback steps; EXECUTE runs them in order with checkpoints.
3. Multi-Agent Collaboration
What: Specialized agents work together (researcher, coder, tester, integrator).
Flow:
- Researcher finds design options
- Coder writes implementation
- Tester runs unit tests
- Integrator merges results
Best for: Complex projects requiring diverse expertise.
Example: Building a feature: one agent researches best practices, another writes code, another tests it, final agent integrates into main branch.
4. Agentic RAG
What: Agents that dynamically retrieve documents, update local indices, and re-run reasoning with newly indexed info.
Flow:
- Agent asks: “What clauses should I include?”
- Tool: retrieve_clauses(context)
- Agent updates knowledge
- Agent re-reasons with new context
Best for: Legal, compliance, and document-heavy domains.
Example: Legal assistant retrieves relevant clauses, extracts Q&A, and refines answer based on latest precedents.
Practical Example: Simple Agent Flow (Pseudocode)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
def run_agent_loop(user_id, user_input, max_iterations=20):
state = load_user_state(user_id)
state.append({"role": "user", "content": user_input})
for i in range(max_iterations):
# 1. Build prompt
prompt = build_prompt(
state=state,
system_prompt=AGENT_SYSTEM_PROMPT,
tool_descriptions=TOOLS_DESCRIPTION
)
# 2. Call LLM
llm_output = call_llm(prompt)
# 3. Check if done
if llm_output.type == "final_answer":
save_state(state)
return llm_output.content
# 4. Execute tool if requested
if llm_output.type == "tool_call":
tool_result = call_tool(
llm_output.tool_name,
llm_output.args
)
state.append({
"role": "assistant",
"content": f"Tool: {llm_output.tool_name}",
"tool_result": tool_result
})
# Handle errors
if tool_result.error:
state.append({
"role": "system",
"content": f"Error: {tool_result.error}"
})
# 5. Check for stuck condition
if stuck_condition(state, i):
escalate_to_human(state, user_id)
return "Escalated to human review."
# Max iterations reached
return "Agent reached max iterations. Escalating..."
Engineering Considerations & Safety
1. Sandboxing Tool Execution
Why: Prevent arbitrary code execution from untrusted LLM outputs.
How:
- Use containers (Docker) for code execution tools
- Restrict filesystem access (read-only mounts)
- Timeout processes after N seconds
2. Audit Logs
Why: Debugging, compliance, anomaly detection.
What to log:
- Every LLM prompt and completion
- Every tool call (inputs, outputs, timing)
- State transitions
- Error conditions
3. Human-in-the-Loop (HITL)
Why: Critical decisions should be reviewable before execution.
When:
- Payment processing
- Account deletions
- Infrastructure changes
- Sensitive data access
How: Flag high-risk actions, notify human, wait for approval before executing.
4. Rate & Cost Control
Set budgets:
- Total token budget per session
- Cost ceiling per user per day
- Fallback: use smaller, cheaper model (SLM) or cached answers if budget exceeded
5. Testing AI Agents
Deterministic tests: Fixed input + sequence of actions = expected output.
Fuzz tests: Vary inputs, check for crashes or nonsensical outputs.
Integration tests: Run with real tools in staging, verify tool calls are correct.
Cost tests: Track token usage per scenario, alert if trending up.
Quick Checklist Before Building an Agent
Use this checklist to validate your agent design:
- ✅ Dynamic tool selection required? (If not, use a pipeline instead)
- ✅ Side-effecting calls? (DB updates, payments — requires HITL)
- ✅ Multi-step, conditional workflow? (If not, a simple prompt may suffice)
- ✅ Clear stop conditions & budgets set? (Max iterations, tokens, time, cost)
- ✅ Tools sandboxed and validated? (No arbitrary code execution)
- ✅ Logging & observability? (Every LLM call, every tool call)
- ✅ HITL for high-risk actions? (Payments, deletions, sensitive operations)
- ✅ Testing strategy in place? (Deterministic + fuzz + integration tests)
- ✅ Cost forecasted? (Token usage per interaction, monthly budget)
- ✅ Escalation path documented? (When to involve humans)
Next Steps
- Evaluate your problem using the decision flow above — do you really need an agent?
- Start simple: Build a ReAct pattern agent with 2-3 basic tools.
- Add safety incrementally: Logging → HITL → Rate limiting.
- Instrument observability: Dashboards for token usage, tool call frequency, error rates.
- Iterate with users: Gather feedback on agent decisions and refine prompts.
Building production-grade AI agents requires discipline, but the payoff—autonomous reasoning, dynamic tool usage, and multi-step planning—is substantial.
Resources
- LangChain Documentation: https://python.langchain.com/docs/agents/
- LangGraph: https://langchain-ai.github.io/langgraph/
- ReAct Paper: https://arxiv.org/abs/2210.03629
- OpenAI Function Calling: https://platform.openai.com/docs/guides/function-calling
- CrewAI: https://github.com/joaomdmoura/crewAI
- AI Agents Tutorial (YouTube): https://www.youtube.com/live/mDk5R5XM6Aw?si=blmlc97SR4dFzEVF
- Building AI Agents (YouTube): https://youtu.be/OKwDzKY_WN8?si=oH0Zj9luD-lMAstG